Naive Bayes
Let’s focus on this table.

Subscript, 

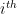
First, we make some basic assertions about the data.
Distributions
Each 

(1)
The following is equivalent:

(2)







(3)
Since this is a probability distribution, we have the constraint 
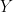

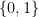
(4)
The following is equivalent:

(5)
The distribution parameters used above are sometimes summarised into a single parameter:

(6)
Likelihood
The probability of seeing this Data, 
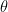

(7)
Note that 





(8)
The “naive” assumption that the dimensions are independent allows us to write the above as follows:

(9)
In Equation (4), the distribution of

(10)
Replacing the distributions defined earlier:

(11)
Equation (11) is the likelihood of a single observation. The likelihood for the entirety of the data is as follows:

(12)
Notice how the product over all observations is limited to a product over all limitations for that particular class.
MLE
To find the maximum likelihood estimate we maximise Equation (12) with respect to 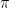


(13)
We go ahead and take the log:
![log P(S | \theta ) = \sum_{d=1}^{D} \sum_{k=0}^{K} \sum_{i:y^{i}=k} log \big[ \Phi_{dk}^{x_d^i} (1-\Phi_{dk})^{1-x_d^i} \big] + \sum_{k=0}^{K} \sum_{i:y^{i}=k} log \big[ \pi_{k}^{I(y^{i}=k)} \big]](https://s0.wp.com/latex.php?latex=log+P%28S+%7C+%5Ctheta+%29+%3D+%5Csum_%7Bd%3D1%7D%5E%7BD%7D+%5Csum_%7Bk%3D0%7D%5E%7BK%7D+%5Csum_%7Bi%3Ay%5E%7Bi%7D%3Dk%7D+log+%5Cbig%5B+%5CPhi_%7Bdk%7D%5E%7Bx_d%5Ei%7D+%281-%5CPhi_%7Bdk%7D%29%5E%7B1-x_d%5Ei%7D+%5Cbig%5D++%2B+%5Csum_%7Bk%3D0%7D%5E%7BK%7D+%5Csum_%7Bi%3Ay%5E%7Bi%7D%3Dk%7D+log+%5Cbig%5B+%5Cpi_%7Bk%7D%5E%7BI%28y%5E%7Bi%7D%3Dk%29%7D+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
![= \sum_{d=1}^{D} \sum_{k=0}^{K} \sum_{i:y^{i}=k} \big[ x_d^i log \Phi_{dk} + (1-x_{d}^{i}) log (1-\Phi_{dk}) \big] + \sum_{k=0}^{K} \sum_{i:y^{i}=k} I(y^{i}=k) log \pi_{k}](https://s0.wp.com/latex.php?latex=%3D+%5Csum_%7Bd%3D1%7D%5E%7BD%7D+%5Csum_%7Bk%3D0%7D%5E%7BK%7D+%5Csum_%7Bi%3Ay%5E%7Bi%7D%3Dk%7D+%5Cbig%5B+x_d%5Ei+log+%5CPhi_%7Bdk%7D+%2B+%281-x_%7Bd%7D%5E%7Bi%7D%29+log+%281-%5CPhi_%7Bdk%7D%29+%5Cbig%5D++%2B+%5Csum_%7Bk%3D0%7D%5E%7BK%7D+%5Csum_%7Bi%3Ay%5E%7Bi%7D%3Dk%7D+I%28y%5E%7Bi%7D%3Dk%29+log+%5Cpi_%7Bk%7D&bg=ffffff&fg=000&s=0&c=20201002)
(14)
Noting that 
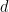

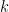


![log P(S | \theta ) = \sum_{d=1}^{D} \sum_{k=0}^{K} \big[ N_{dk} log \Phi_{dk} + (1-N_{dk}) log (1-\Phi_{dk}) \big] + \sum_{k=0}^{K} n_k log \pi_{k}](https://s0.wp.com/latex.php?latex=log+P%28S+%7C+%5Ctheta+%29+%3D+%5Csum_%7Bd%3D1%7D%5E%7BD%7D+%5Csum_%7Bk%3D0%7D%5E%7BK%7D+%5Cbig%5B+N_%7Bdk%7D+log+%5CPhi_%7Bdk%7D+%2B+%281-N_%7Bdk%7D%29+log+%281-%5CPhi_%7Bdk%7D%29+%5Cbig%5D++%2B+%5Csum_%7Bk%3D0%7D%5E%7BK%7D+n_k+log+%5Cpi_%7Bk%7D&bg=ffffff&fg=000&s=0&c=20201002)
(15)
We apply the constraint on

(16)
Taking the derivative of Equation (16) recovers the constraint:

(17)
Next we take the derivative with respect to 

(18)
Summing Equation (18):

(19)
Putting Equation (19) into Equation (18) we obtain a solution for 

(20)
Similarly, we obtain 
![\frac{\partial ll}{\partial \phi_{dk}} = \sum_{i:y^i=k} \big[ \frac{x_d^i}{\phi_{dk}} - \frac{1-x_d^i}{1-\phi_{dk}} \big] = \frac{N_{dk}}{\phi_{dk}} - \frac{1-N_{dk}}{1-\phi_{dk}} = 0](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+ll%7D%7B%5Cpartial+%5Cphi_%7Bdk%7D%7D+%3D+%5Csum_%7Bi%3Ay%5Ei%3Dk%7D+%5Cbig%5B+%5Cfrac%7Bx_d%5Ei%7D%7B%5Cphi_%7Bdk%7D%7D+-+%5Cfrac%7B1-x_d%5Ei%7D%7B1-%5Cphi_%7Bdk%7D%7D+%5Cbig%5D+%3D+%5Cfrac%7BN_%7Bdk%7D%7D%7B%5Cphi_%7Bdk%7D%7D+-+%5Cfrac%7B1-N_%7Bdk%7D%7D%7B1-%5Cphi_%7Bdk%7D%7D+%3D+0&bg=ffffff&fg=000&s=0&c=20201002)
(21)
Solving for 

(22)
We have the following MLE solutions:

(23)
where


(24)
Classifying with Naive Bayes
Using the above, given a new data point 



(25)
which is just Equation (11) with the MLE solutions for a single observation and for class

(26)
Let’s test it out on Table 1 for only the first 3 columns (











(27)
Plugging these into Equation (26) we find 



(28)
This makes sense since, according to the data, if you get a data point 





Bayesian Naive Bayes
The problem with the example above is that 





Let’s look at the general form of Equation (28) to see how we would classify, 


(29)
Note that the last equality in Equation (29) makes the assumption that the random variables of different dimensions are independent from each other. We know from our previous assumption (Equation (4)) that 


(30)
Applying the definition of conditional probability:

(31)
Notice that in the last equality of Equation (31) we dropped the dependence of the first term on the data (

(32)
In Equation (32) we skipped the step of explicitly applying the theorem of total probability as we did in Equation (31). Putting equations (31) and (32) into Equation (29):
![P(Y=k|x,\mathcal{S}) \propto \left[\prod_{d=1}^{D} \int_{\phi_{dk}}Ber(x_d | Y=k,\phi_{dk})P(\phi_{dk} |\mathcal{S})d\phi_{dk} \right] \left[\int_{\pi}Cat(Y=k|\pi)P(\pi|\mathcal{S})d\pi \right]](https://s0.wp.com/latex.php?latex=P%28Y%3Dk%7Cx%2C%5Cmathcal%7BS%7D%29+%5Cpropto+%5Cleft%5B%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cint_%7B%5Cphi_%7Bdk%7D%7DBer%28x_d+%7C+Y%3Dk%2C%5Cphi_%7Bdk%7D%29P%28%5Cphi_%7Bdk%7D+%7C%5Cmathcal%7BS%7D%29d%5Cphi_%7Bdk%7D+%5Cright%5D+%5Cleft%5B%5Cint_%7B%5Cpi%7DCat%28Y%3Dk%7C%5Cpi%29P%28%5Cpi%7C%5Cmathcal%7BS%7D%29d%5Cpi+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
(33)
We removed the denominator in Equation (29) and hence Equation (33) is a proportionality equation. Equation (33) contains 2 terms that are posterior probabilities for the parameters:

(34)
where

(35)
If we let

(36)
so that

(37)
and

(38)
so that
![P(\pi|\alpha) = Dir(\pi|\alpha)=\frac{1}{B(\alpha)}\prod_{k=0}^{K} \pi_{k}^{\alpha_k-1}I(\pi \in [0,1]^K)](https://s0.wp.com/latex.php?latex=P%28%5Cpi%7C%5Calpha%29+%3D+Dir%28%5Cpi%7C%5Calpha%29%3D%5Cfrac%7B1%7D%7BB%28%5Calpha%29%7D%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cpi_%7Bk%7D%5E%7B%5Calpha_k-1%7DI%28%5Cpi+%5Cin+%5B0%2C1%5D%5EK%29+&bg=ffffff&fg=000&s=0&c=20201002)
(39)
Equation (35) becomes
![P(\theta) = \left[ \prod_{d=1}^{D} \prod_{k=0}^{K} \frac{1}{B(\beta_0,\beta_1)} \phi_{dk}^{\beta_0-1}(\phi_{dk})^{\beta_1-1} \right] \left[ \frac{1}{B(\alpha)}\prod_{k=0}^{K} \pi_{k}^{\alpha_k-1} \right]](https://s0.wp.com/latex.php?latex=P%28%5Ctheta%29+%3D+%5Cleft%5B+%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D++%5Cfrac%7B1%7D%7BB%28%5Cbeta_0%2C%5Cbeta_1%29%7D+%5Cphi_%7Bdk%7D%5E%7B%5Cbeta_0-1%7D%28%5Cphi_%7Bdk%7D%29%5E%7B%5Cbeta_1-1%7D++%5Cright%5D+%5Cleft%5B++%5Cfrac%7B1%7D%7BB%28%5Calpha%29%7D%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cpi_%7Bk%7D%5E%7B%5Calpha_k-1%7D+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
(40)
such that ![\pi \in [0,1]^K](https://s0.wp.com/latex.php?latex=%5Cpi+%5Cin+%5B0%2C1%5D%5EK++&bg=ffffff&fg=000&s=0&c=20201002)
Equation (40) is in the same form as the likelihood. Putting equations (12) and (40) into (34) to get the posterior:
![P(\theta|\mathcal{S}) = a \times \left[ \prod_{d=1}^{D} \prod_{k=0}^{K} \prod_{i:y^{i}=k} \Phi_{dk}^{x_d^i} (1-\Phi_{dk})^{1-x_d^i} \right] \left[ \prod_{k=0}^{K} \prod_{i:y^{i}=k} \pi_{k}^{I(y^{i}=k)} \right]](https://s0.wp.com/latex.php?latex=P%28%5Ctheta%7C%5Cmathcal%7BS%7D%29+%3D+a+%5Ctimes+%5Cleft%5B+%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cprod_%7Bi%3Ay%5E%7Bi%7D%3Dk%7D+%5CPhi_%7Bdk%7D%5E%7Bx_d%5Ei%7D+%281-%5CPhi_%7Bdk%7D%29%5E%7B1-x_d%5Ei%7D+%5Cright%5D+%5Cleft%5B++%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cprod_%7Bi%3Ay%5E%7Bi%7D%3Dk%7D+%5Cpi_%7Bk%7D%5E%7BI%28y%5E%7Bi%7D%3Dk%29%7D+%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![\times \left[ \prod_{d=1}^{D} \prod_{k=0}^{K} \frac{1}{B(\beta_0,\beta_1)} \phi_{dk}^{\beta_0-1}(\phi_{dk})^{\beta_1-1} \right] \left[ \frac{1}{B(\alpha)}\prod_{k=0}^{K} \pi_{k}^{\alpha_k-1} \right]](https://s0.wp.com/latex.php?latex=%5Ctimes+%5Cleft%5B+%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D++%5Cfrac%7B1%7D%7BB%28%5Cbeta_0%2C%5Cbeta_1%29%7D+%5Cphi_%7Bdk%7D%5E%7B%5Cbeta_0-1%7D%28%5Cphi_%7Bdk%7D%29%5E%7B%5Cbeta_1-1%7D++%5Cright%5D+%5Cleft%5B++%5Cfrac%7B1%7D%7BB%28%5Calpha%29%7D%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cpi_%7Bk%7D%5E%7B%5Calpha_k-1%7D+%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002)
(41)
where the denominator in Equation (34) has been absorbed into the constant 
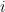

![P(\theta|\mathcal{S}) = a \times \left[ \prod_{d=1}^{D} \prod_{k=0}^{K} \phi_{dk}^{\sum_{i:y^i=k} x_d^i} (1-\phi_{dk})^{\sum_{i:y^i=k} (1-x_d^i)} \prod_{k=0}^{K}\pi_k^{\sum_{i:y^i=k}I(y^i=k)} \right]](https://s0.wp.com/latex.php?latex=P%28%5Ctheta%7C%5Cmathcal%7BS%7D%29+%3D+a+%5Ctimes+%5Cleft%5B+%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cphi_%7Bdk%7D%5E%7B%5Csum_%7Bi%3Ay%5Ei%3Dk%7D+x_d%5Ei%7D+%281-%5Cphi_%7Bdk%7D%29%5E%7B%5Csum_%7Bi%3Ay%5Ei%3Dk%7D+%281-x_d%5Ei%29%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D%5Cpi_k%5E%7B%5Csum_%7Bi%3Ay%5Ei%3Dk%7DI%28y%5Ei%3Dk%29%7D+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![= a \times \left[ \prod_{d=1}^{D} \prod_{k=0}^{K} \phi_{dk}^{N_{dk}} (1-\phi_{dk})^{n_k-N_{dk}} \prod_{k=0}^{K}\pi_k^{n_k} \right]](https://s0.wp.com/latex.php?latex=%3D+a+%5Ctimes+%5Cleft%5B+%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cphi_%7Bdk%7D%5E%7BN_%7Bdk%7D%7D+%281-%5Cphi_%7Bdk%7D%29%5E%7Bn_k-N_%7Bdk%7D%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D%5Cpi_k%5E%7Bn_k%7D+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![= a \times \left[ \prod_{d=1}^{D} \prod_{k=0}^{K} \frac{1}{B(\beta_0,\beta_1)} \phi_{dk}^{N_{dk} + \beta_0-1} (1-\phi_{dk})^{n_k-N_{dk}+\beta_1-1} \prod_{k=0}^{K}\frac{1}{B(\alpha)}\pi_k^{n_k + \alpha_k - 1} \right]](https://s0.wp.com/latex.php?latex=%3D+a+%5Ctimes+%5Cleft%5B+%5Cprod_%7Bd%3D1%7D%5E%7BD%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D+%5Cfrac%7B1%7D%7BB%28%5Cbeta_0%2C%5Cbeta_1%29%7D++%5Cphi_%7Bdk%7D%5E%7BN_%7Bdk%7D+%2B+%5Cbeta_0-1%7D+%281-%5Cphi_%7Bdk%7D%29%5E%7Bn_k-N_%7Bdk%7D%2B%5Cbeta_1-1%7D+%5Cprod_%7Bk%3D0%7D%5E%7BK%7D%5Cfrac%7B1%7D%7BB%28%5Calpha%29%7D%5Cpi_k%5E%7Bn_k+%2B+%5Calpha_k+-+1%7D+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)

(42)
There are two observations which informed the last equality in Equation (42): The posterior is a probability which satisfies the axioms of a probability measure; the penultimate equality in Equation (42) has the same form as a Beta distribution and a Dirichlet distribution. Then these distributions must indeed be the Beta and Dirichlet distributions with 
Putting Equation (42) into Equation (33) gives us a way for making a classification (Bayesian Naive Bayes):







(43)
In the second equality we just replaced the definitions of the Bernoulli and the Categorical distributions. In the last equality we split the product into to terms with power 1 and terms with power 0. Notice that the integrals are the expectations of the corresponding distributions (i.e. let 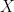
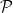

![\int_x x P(x)dx = E_{\mathcal{P}}[x]](https://s0.wp.com/latex.php?latex=%5Cint_x+x+P%28x%29dx+%3D+E_%7B%5Cmathcal%7BP%7D%7D%5Bx%5D&bg=ffffff&fg=000&s=0&c=20201002)
![P(Y=k|x,\mathcal{S}) \propto \prod_{d:x_d=1}E_{\phi_{dk}}[\phi_{dk}] \prod_{d:x_d=0}E_{\phi_{dk}}[1-\phi_{dk}] E_{\pi}[\pi_k]](https://s0.wp.com/latex.php?latex=P%28Y%3Dk%7Cx%2C%5Cmathcal%7BS%7D%29+%5Cpropto+%5Cprod_%7Bd%3Ax_d%3D1%7DE_%7B%5Cphi_%7Bdk%7D%7D%5B%5Cphi_%7Bdk%7D%5D+%5Cprod_%7Bd%3Ax_d%3D0%7DE_%7B%5Cphi_%7Bdk%7D%7D%5B1-%5Cphi_%7Bdk%7D%5D+E_%7B%5Cpi%7D%5B%5Cpi_k%5D&bg=ffffff&fg=000&s=0&c=20201002)

(44)
The mean of a 





(45)
Typically, for an uninformative prior we set 

Classifying with Bayesian Naive Bayes
Now we will generate a new classification for the same observation 








(46)
The final probabilities for each class are then:



(47)
Just as in Equation (28), we have 0 as the most likely class with class 2 the second most likely. However, this time we predict class 1 with a non-zero probability.